Three weeks ago I ran an experiment: pit three Chinese AI models against three American ones, have them predict 14 World Cup group stage matches, and see who got closer to reality.
The results are in.
Quick Recap
Six models. Same 14 matches. Three Chinese (Kimi, Doubao, Qianwen), three American (ChatGPT, Gemini, Claude). They agreed on 12 out of 14. I bought two ¥2 tickets — the only real difference was match 9: Norway vs Senegal.
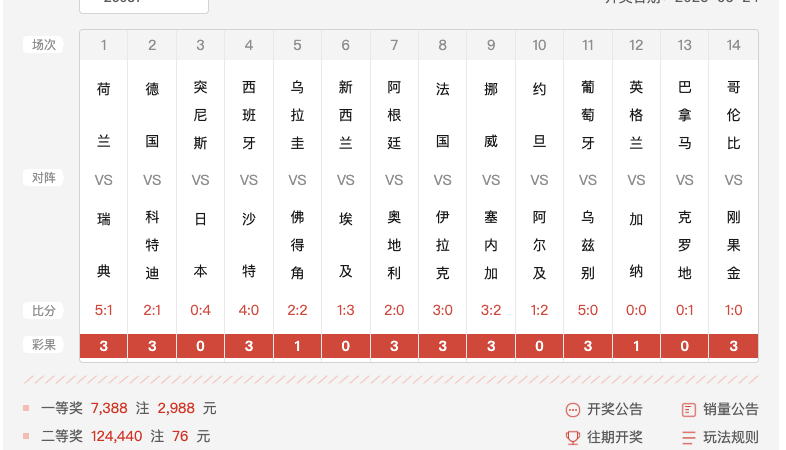
The 14 Results
| # | Match | AI Prediction | Actual | ✓/✗ |
|---|---|---|---|---|
| 1 | Netherlands vs Sweden | 5: NED win / ChatGPT: Draw | NED 5-1 SWE | ✓ 5 ✗ ChatGPT |
| 2 | Germany vs Ivory Coast | All 6: Germany win | GER 2-1 CIV | ✓ all |
| 3 | Tunisia vs Japan | All 6: Japan win | TUN 0-4 JPN | ✓ all |
| 4 | Spain vs Saudi Arabia | All 6: Spain win | ESP 4-0 KSA | ✓ all |
| 5 | Uruguay vs Cape Verde | All 6: Uruguay win | URU 2-2 CPV | ✗ all |
| 6 | New Zealand vs Egypt | All 6: Egypt win | NZL 1-3 EGY | ✓ all |
| 7 | Argentina vs Austria | All 6: Argentina win | ARG 2-0 AUT | ✓ all |
| 8 | France vs Iraq | All 6: France win | FRA 3-0 IRQ | ✓ all |
| 9 | Norway vs Senegal | Kimi/Doubao/Claude: NOR win • ChatGPT/Gemini/Qianwen: Draw | NOR 3-2 SEN | ✓ Kimi/Doubao/Claude ✗ others |
| 10 | Jordan vs Algeria | All 6: Algeria win | JOR 1-2 ALG | ✓ all |
| 11 | Portugal vs Uzbekistan | All 6: Portugal win | POR 5-0 UZB | ✓ all |
| 12 | England vs Ghana | All 6: England win | ENG 0-0 GHA | ✗ all |
| 13 | Panama vs Croatia | All 6: Croatia win | PAN 0-1 CRO | ✓ all |
| 14 | Colombia vs DR Congo | All 6: Colombia win | COL 1-0 COD | ✓ all |
The Scorecard
| Model | Correct/14 | Accuracy |
|---|---|---|
| Kimi (China) | 12/14 | 85.7% |
| Doubao (China) | 12/14 | 85.7% |
| Qianwen (China) | 11/14 | 78.6% |
| ChatGPT (US) | 10/14 | 71.4% |
| Gemini (US) | 11/14 | 78.6% |
| Claude (US) | 12/14 | 85.7% |
| China AI avg | 35/42 | 83.3% |
| US AI avg | 33/42 | 78.6% |
The One That Mattered: Norway vs Senegal
Actual result: Norway 3–2 Senegal.
Norway won. Three models called it: Kimi, Doubao — and Claude.
Here’s the footnote: Claude crossed camp lines. The split wasn’t cleanly Chinese vs. American. Kimi, Doubao, and Claude trusted the momentum; ChatGPT, Gemini, and Qianwen chose caution. What looked like a culture gap turned out to be a form-vs-structure debate. Form won.
The Bigger Story: Two Matches Broke Everyone
Match 5: Uruguay vs Cape Verde. Every model predicted Uruguay win. Final: 2–2.
Match 12: England vs Ghana. Every model predicted England win. Final: 0–0.
When six systems that can’t communicate converge on the same wrong answer, it’s a shared blind spot. AI models pattern-match the stronger team and call it done. What they miss: how often the weaker team simply doesn’t lose.
The Tickets

China AI ticket (Norway win): 12/14 correct. Lost — two draws broke it.
US AI ticket (Draw on Norway): 11/14. Also lost. Combined spend: ¥4. Combined return: ¥0.
Being right on the contested call doesn’t win if you share everyone else’s blind spots.
What’s Next
I’ll run the same experiment on the quarterfinals. Part 1 has the original predictions.
Which surprised you more — Norway, or the two draws that broke everyone?
Free Tools From This Blog
Leave a Reply